En realidad, una memoria de traducción coincide plenamente con un corpus lingüístico de tipo paralelo, pues contiene una selección de textos debidamente alineados con sus traducciones. Esta herramienta puede resultar de gran ayuda al traductor, llegando incluso a constituir una alternativa a los diccionarios. No es una simple base de datos, pues incorpora otro tipo de herramientas informáticas -glosarios, correctores, etc.
Si bien cualquiera de las herramientas -relacionadas con corpus de tipo paralelo- señaladas en la entrada anterior servirían como ejemplo para esta sección, me gustaría mencionar una nueva. Se trata de la memoria de traducción online de Glosbe de uso libre, con más de 1.000.000.000 de frases traducidas, y que también constituye un entorno colaborativo.
Algunas de esas MT poseen potentes motores de búsqueda que permiten explorar textos e identificar patrones lingüísticos y terminológicos comunes. Pueden localizar segmentos exactos al introducido, mostrando una coincidencia del 100%; pero también señalan segmetos de coincidencia parcial -que se denomina fuzzy match. En el caso de que el segmento introducido no aparezca en la MT, el usuario puede introducirlo manualmente quedando así almacenado para un futuro uso -acción que se demonina leveraging.
El proceso de búsqueda en una MT es sencillo: en primer lugar, el traductor introduce el segmento o término que pretende traducir. A continuación, el programa analiza y busca en su BDD coincidencias totales o parciales del texto introducido. Tras mostrárselas al traductor, éste las revisa, aceptando o rechazando la propuesta; y en caso de modificarla, la versión alterada queda almacenada en la propia BDD. Como consecuencia de este último paso, el volumen de una MT va creciendo por y alimentándose de su propio uso; por ello cuanto más se acceda a ella, más trabajo se ahorrará el traductor que la use.
Memorias de Traducción Compartidas
Debido a ese flujo autogenerador de contenidos, parece lógico plantearse la posibilidad y los beneficios de elaborar memorias de traducción compartidas; sobre todo en aquellos casos en los que se trate de un proyecto de traducción grande, en el que el proveedor trabaje con más de un traductor. En este caso, el propio proveedor sería responsabile de las labores de preprocesación, gestión y posterior ampliación de las MT utilizadas.
Para el cliente el uso de MTC tiene numerosos beneficios, como: reducir de costes y fomentar la competitivadad entre proveedores, disponer de proveedores especializados que compartan sus MT, evitar los riesgos de depender de un único proveedor, etc. Para el proveedor, poseer una MTC competente incrementa sus posibilidades en el mercado, demostrando su superioridad frente a otros proveedores y fomentando la calidad de las MT.
De forma general, la centralización que se produce con las MTC reduce costes y disminuye gastos con respecto al mantenimiento de varias MT, además de aumentar la fiablidad y las posibilidades que éstas ofrecen. Sin embargo no hay que subestimar la complejidad y dedicación que exige la gestión de MTC, pues su valor y calidad recaen directamente en la capacidad del proveedor para desempeñar dichas funciones de mantenimiento y ampliación de forma correcta.
Como ejemplo de MTC está la Very Large Translation Memory (VLTM) de Wordfast, de uso gratuito, y otro ejemplo más de entorno colaborativo. Para los interesados, introduzco aquí un link a varios de sus tutoriales para sacar el máximo rendimiento a la herramienta.
BIBLIOGRAFÍA:
- http://es.wikipedia.org/
- http://glosbe.com/
- http://www.wordfast.com/
domingo, 26 de febrero de 2012
sábado, 18 de febrero de 2012
Gestión de corpus multilingës
Como ocurre en muchas áreas de investigación lingüística, la utilización de un corpus lingüístico -o colecciones de textos que han sido seleccionados y compilados según unas características determinadas- tiene unas aplicaciones muy útiles. Normalmente empleados en análisis estadísticos y/o testeo de hipótesis, permiten señalar la frecuencia con que se uilizan términos o validar normas lingüísticas en un entorno específico.
En el caso concreto de la traducción el interés reside en la creación y el posterior uso de corpus paralelos, en el sentido de textos que son traducciones unos de otros. Hoy en día quizás consista en una herramienta íntimamente relacionada con la lingüística computacional, puesto que el conjunto de textos suelen encontrarse en formato digital. Sin embargo, existe un notorio ejemplo histórico de corpus paralelo: la piedra de Rosetta.
Como resulta lógico, la eficacia de este recurso depende directamente de la estructuración de su contenido; es decir, que los textos y sus traducciones estén bien alineados, incluyendo el mismo número de párrafos e incluso frases. Este proceso de alineación de textos es laborioso y lleva tiempo, por lo que antes de elaborar un corpus paralelo propio debemos conocer algunas herramientas que nos puedan ayudar en nuestra tarea.
En clase hablamos de y la herramienta de código libre Bitext2TMX, que nos permitía alinear dos textos para crear una futura memoria de traducción. También nos adentramos en el WinAlign de Trados -aquí una guía básica para empezar a usar el programa- y el alineador de DéjàVu. Investigando por mi cuenta he encontrado otros materiales que resultarían útiles en la elaboración de nuestro corpus paralelo individual, como la herramienta GIZA++, que ha sido recientemente actualizada y está publicada bajo una licencia copyleft GNU. Por nombrar otros, están también el programa open source Uplug y la herramienta ISA - Interactive Sentence Alignment.

A continuación señalaré algunos de estos corpus paralelos que he ido encontrando durante mi investigación sobre el tema. Uno de los analizado en clase es ParaConc, que a pesar de estar aún en versión beta, posee notoriedad y permite alinear textos, buscar y traducir términos y expresiones, etc. en una gran variedad de lenguas -incluyendo chino, japonés, árabe, etc.
A pesar de no ser un corpus parelelo sino simplemente un corpus lingüístico hispano, me parece interesante resaltar el proyecto del laboratorio lingüístico Molinolabs, y concretamente su corpus formado a partir de artículos de prensa de España, Argentina y México. Además del corpus, posee silabeador, acentuador, anagramador, lematizador y otros recursos más que en mi opinión podrían resultar de gran ayuda.
A parte del material disponible generado por los debates del parlamento europeo, ya comentado en clase, merece mención el corpus paralelo multilingüe JRC-Acquis. Con más de 20 millones de palabras en 230 pares de lenguas, es actualizado constamentemente y constituye el conjunto de leyes aplicables en los estados miembros de la Unión Europea, desde 1950 hasta nuestros días.
Otro de estos recursos es Tatoeba, una gran base de datos de oraciones completas y expresiones traducidas a casi 100 lenguas distintas. Ha sido publicada bajo las licencias Creative Commons por lo que libre y de fácil acceso académico, además de ser también un entorno colaborativo. Aquí el vídeo de presentación:
Para terminar, personalmente me ha resultado interesante un documento que he encontrado en el que su autor explica el proceso de preparación de un corpus paralelo, paso a paso; desde la recopilación de textos a la metodología de alineación empleada.
BIBLIOGRAFÍA:
- http://es.wikipedia.org/
- http://bitext2tmx.sourceforge.net
- http://www-i6.informatik.rwth-aachen.de/
- http://www.gnu.org/
- http://blog.quillslanguage.com/
- http://sourceforge.net/
- http://www.athel.com/
- http://tatoeba.org/
- http://www.molinolabs.com/
- http://www.statmt.org/
En el caso concreto de la traducción el interés reside en la creación y el posterior uso de corpus paralelos, en el sentido de textos que son traducciones unos de otros. Hoy en día quizás consista en una herramienta íntimamente relacionada con la lingüística computacional, puesto que el conjunto de textos suelen encontrarse en formato digital. Sin embargo, existe un notorio ejemplo histórico de corpus paralelo: la piedra de Rosetta.
Como resulta lógico, la eficacia de este recurso depende directamente de la estructuración de su contenido; es decir, que los textos y sus traducciones estén bien alineados, incluyendo el mismo número de párrafos e incluso frases. Este proceso de alineación de textos es laborioso y lleva tiempo, por lo que antes de elaborar un corpus paralelo propio debemos conocer algunas herramientas que nos puedan ayudar en nuestra tarea.
En clase hablamos de y la herramienta de código libre Bitext2TMX, que nos permitía alinear dos textos para crear una futura memoria de traducción. También nos adentramos en el WinAlign de Trados -aquí una guía básica para empezar a usar el programa- y el alineador de DéjàVu. Investigando por mi cuenta he encontrado otros materiales que resultarían útiles en la elaboración de nuestro corpus paralelo individual, como la herramienta GIZA++, que ha sido recientemente actualizada y está publicada bajo una licencia copyleft GNU. Por nombrar otros, están también el programa open source Uplug y la herramienta ISA - Interactive Sentence Alignment.
A continuación señalaré algunos de estos corpus paralelos que he ido encontrando durante mi investigación sobre el tema. Uno de los analizado en clase es ParaConc, que a pesar de estar aún en versión beta, posee notoriedad y permite alinear textos, buscar y traducir términos y expresiones, etc. en una gran variedad de lenguas -incluyendo chino, japonés, árabe, etc.
A pesar de no ser un corpus parelelo sino simplemente un corpus lingüístico hispano, me parece interesante resaltar el proyecto del laboratorio lingüístico Molinolabs, y concretamente su corpus formado a partir de artículos de prensa de España, Argentina y México. Además del corpus, posee silabeador, acentuador, anagramador, lematizador y otros recursos más que en mi opinión podrían resultar de gran ayuda.
A parte del material disponible generado por los debates del parlamento europeo, ya comentado en clase, merece mención el corpus paralelo multilingüe JRC-Acquis. Con más de 20 millones de palabras en 230 pares de lenguas, es actualizado constamentemente y constituye el conjunto de leyes aplicables en los estados miembros de la Unión Europea, desde 1950 hasta nuestros días.
Otro de estos recursos es Tatoeba, una gran base de datos de oraciones completas y expresiones traducidas a casi 100 lenguas distintas. Ha sido publicada bajo las licencias Creative Commons por lo que libre y de fácil acceso académico, además de ser también un entorno colaborativo. Aquí el vídeo de presentación:
Para terminar, personalmente me ha resultado interesante un documento que he encontrado en el que su autor explica el proceso de preparación de un corpus paralelo, paso a paso; desde la recopilación de textos a la metodología de alineación empleada.
BIBLIOGRAFÍA:
- http://es.wikipedia.org/
- http://bitext2tmx.sourceforge.net
- http://www-i6.informatik.rwth-aachen.de/
- http://www.gnu.org/
- http://blog.quillslanguage.com/
- http://sourceforge.net/
- http://www.athel.com/
- http://tatoeba.org/
- http://www.molinolabs.com/
- http://www.statmt.org/
jueves, 16 de febrero de 2012
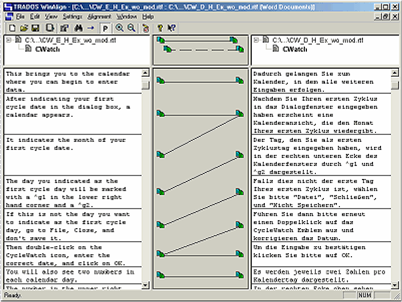
Alineación de textos: WinAlign de Trados y el alineador de DéjàVu
Dedicaré una entrada de este blog a los alineadores de texto, extremadamente útiles para un traductor (sobre todo cuando más extensa sea su cartera de textos paralelos). Si bien podemos crearnos nuestro propio alineador con una hoja de cáculo Excel, existen dos herramientas que funcionan bien y que son muy concurridas: el WinAlign de TRADOS y el alineador de DÉJÀVU.
WinAlign de TRADOS

Alineador de DÉJÀVU

Como mencionaba al inicio de la entrada, cuanto más amplia sea la cartera de textos paralelos de un traductor, mejores serán los resultados de la alineación de texto; en definitiva, las memorias de traducción (que analizaré en la siguiente entrada) que posean serán más efectivas.
Sin embargo, no sólo importa el volumen de textos; sino también la calidad de la alineación, puesto que los resultados que de ella derivan serán más sólidos. Para esto, debemos tener en cuenta una serie de factores que nos ayudarán a alinear de forma correcta los textos que vayamos incluyendo a nuestras memorias. Algunos de esos factores son:
· Comprobar que los textos en lengua origen y meta son adecuados. Si comparamos un texto con otro que no es su traducción, o que no posee la misma temática, el proceso de alineación puede resultar inútil.
· Comprobar que dichos textos tienen el mismo formato de archivo. En caso contrario, la alineación será infructuosa; la herramienta no será capaz de contrastar y comparar los bloques de texto supuestamente paralelos.
· Especificar las lenguas de origen y meta. Lo más idóneo es organizar los textos en base a su temática, y a un par de lenguas. El utilizar más de un par puede provocar que el programa cometa errores comparativos (además de que la memoria de traducción final será menos específica).
· Seleccionar los archivos correspondientes. Puedes trabajar en uno o más archivos simultánteamente; el porcentaje de un texto que haya sido ya comparado se guarda, y el resto se puede continuar alineando en otro momento.
· Seguir las instrucciones de la herramienta de alineación elegida.
· Exportar el resultado en un formato compatible con el programa de memoria que se vaya a utilizar. En el caso de que sea un alineador incorporado, como el WinAlign que se incluye en el paquete de Trados o el alineador interno de DéjàVu, este proceso se realizará de forma automática.
· Seleccionar bien los textos paralelos. No todos los textos son adecuados para alimentar una MT; cuando más específica sea la temática, además de limitar el contenido a un único par de lenguas, más productiva será la memoria.
Para cerrar esta entrada, señalar que incluso cuando hemos realizado correctamente todos los pasos anteriores, no está de más revisar la alineación propuesta por el programa. La puntuación varía de lengua a lengua, lo que puede provocar que los segmentos relacionados por el programa no sean correctos, o resulten poco válidos para nuestra futura labor traductora.
WinAlign de TRADOS
Alineador de DÉJÀVU

Como mencionaba al inicio de la entrada, cuanto más amplia sea la cartera de textos paralelos de un traductor, mejores serán los resultados de la alineación de texto; en definitiva, las memorias de traducción (que analizaré en la siguiente entrada) que posean serán más efectivas.
Sin embargo, no sólo importa el volumen de textos; sino también la calidad de la alineación, puesto que los resultados que de ella derivan serán más sólidos. Para esto, debemos tener en cuenta una serie de factores que nos ayudarán a alinear de forma correcta los textos que vayamos incluyendo a nuestras memorias. Algunos de esos factores son:
· Comprobar que los textos en lengua origen y meta son adecuados. Si comparamos un texto con otro que no es su traducción, o que no posee la misma temática, el proceso de alineación puede resultar inútil.
· Comprobar que dichos textos tienen el mismo formato de archivo. En caso contrario, la alineación será infructuosa; la herramienta no será capaz de contrastar y comparar los bloques de texto supuestamente paralelos.
· Especificar las lenguas de origen y meta. Lo más idóneo es organizar los textos en base a su temática, y a un par de lenguas. El utilizar más de un par puede provocar que el programa cometa errores comparativos (además de que la memoria de traducción final será menos específica).
· Seleccionar los archivos correspondientes. Puedes trabajar en uno o más archivos simultánteamente; el porcentaje de un texto que haya sido ya comparado se guarda, y el resto se puede continuar alineando en otro momento.
· Seguir las instrucciones de la herramienta de alineación elegida.
· Exportar el resultado en un formato compatible con el programa de memoria que se vaya a utilizar. En el caso de que sea un alineador incorporado, como el WinAlign que se incluye en el paquete de Trados o el alineador interno de DéjàVu, este proceso se realizará de forma automática.
· Seleccionar bien los textos paralelos. No todos los textos son adecuados para alimentar una MT; cuando más específica sea la temática, además de limitar el contenido a un único par de lenguas, más productiva será la memoria.
Para cerrar esta entrada, señalar que incluso cuando hemos realizado correctamente todos los pasos anteriores, no está de más revisar la alineación propuesta por el programa. La puntuación varía de lengua a lengua, lo que puede provocar que los segmentos relacionados por el programa no sean correctos, o resulten poco válidos para nuestra futura labor traductora.
viernes, 10 de febrero de 2012
Wikipedia y la web como "entorno colaborativo"
Cuando aplicamos el término "entorno colaborativo", generalmente estamos haciendo referencia a una red virtual que facilita la colaboración e interacción entre los miembros de una comunidad online. En este sentido, se está potenciando al máximo la característica comunicativa de la informática; su capacidad para desarrollar de forma espontánea toda un sistema de información y proyectos, núcleos socioculturales, servicios informativos, etc. Y todo resulta posible gracias a y a través de la Web 2.0, un término complejo de explicar pero que en líneas generales se refiere a un conjunto de plataformas que facilitan y favorecen esa interacción online. Para saber más sobre la Web 2.0 yo recomiendo este artículo, que detalla cuáles son sus orígenes, sus propiedades básicas, y sus diferencias con respecto a la Web 1.0.
Estos entornos colaborativos abarcan desde los editores de documentos compartidos como Google Docs, sitios web abiertos y editables como los wikis, foros y blogs como MySpace o Blogger, o incluso las notorias redes sociales como Twitter o Facebook, que incluyen perfiles y herramientas de conexión para aportan un enfoque colaborativo dentro de la comunidad.
Todas estas plataformas virtuales (e inumerables más) se han convertido en herramientas muy potentes dentro de nuestra sociedad; tanto a nivel personal como educativo, profesional, lúdico, publicitario, etc. En lo que a nosotros respecta, las TICs se presentan como un conjunto de soluciones que permiten crear y organizar entornos, fomentando un flujo dinámico de intercambio de información. Como futuros traductores estas herramientas pueden ser de gran utilidad en nuestras prácticas traductológicas; incluso traducir documentos pertenecientes a ese propio entorno puede llegar a ser nuestro objetivo. Por ello en esta entrada profundizaremos en el funcionamiento de Wikipedia, por ser probablemente el entorno colaborativo más notorio y extenso. Además de contener un número ridículo de artículos y trabajar con casi 300 lenguas, posee una red de herramientas "hermanas" dedicadas a variados dominios: un diccionario, una base de datos de citas célebres, un banco de libros de contenido libre, etc.
No hay nada que ilustre con mayor claridad la notoriedad de Wikipedia como el hecho de que resulta innecesrio explicar en qué consiste dicha web. Cualquier persona que esté leyendo este blog habrá utilizado casi de forma diaria dicha plataforma; y un porcentaje representativo habrá incluso participado en el proyecto editando entradas o utilizándolo como referencia. Sin embargo, dicha notoriedad resulta a veces un arma de doble filo: la pluralidad de usuarios y sus objetivos dispares a veces provocan que la información que Wikipedia contiene sea tendenciosa o falsa. Y a menudo -y es ésta la cuestión que más nos interesa-, las traducciones que se han efectuado de una lengua a otra han sido descuidadas y negligentes, lo que acarrea malentendidos y falsos sentidos.
Por ello, si queremos formar parte de este gran proyecto colaborativo, lo primero que debemos hacer es repasar las normas generales y ayudas básicas que esta web proporciona en su "Portal de la comunidad". En primer lugar, para la orientación de nuevos usuarios, Wikipedia cuenta con una serie de ayudas como una introducción general a cuestiones básicas, una zona de pruebas para practicar creando nuevas entradas, e incluso un programa de tutorías en el que un conjunto de usuarios veteranos voluntarios se ofrecen a actuar como tutores.
También cabe resaltar una sección que a mi modo de ver resulta muy certera: una especie de declaración de lo que Wikipedia no es. Creo que este aspecto merece mención pues saca a la luz lo revolucionario de Wikipedia en sí; lo que hizo que desde sus orígenes surgiera como una propuesta innovadora que relegaría al pasado a las ya arcaicas colecciones enciclopédicas.
Dado el amplio abanico de posibilidades de colaboración dentro de este entorno, considero que lo más útil sería recalcar también aquellos sectores en los que la labor de un traductor resulta más conveniente y favorable. En este sentido Wikipedia cuenta con la sección "Cómo puedes colaborar", en la que solicitan individuos bilingües tanto para traducir desde otras wikipedias al español, como para corregir traducciones "dudosas" ya emitidas. Por otro lado, proponen una serie de recomendaciones a la hora de traducir un artículo; así como un taller idiomático en el que ofrecen apoyo en la traducción de pasajes, frases, modismos, argots, etc.
Resumiendo, por un lado, Wikipedia representa para futuros traductores como nosotros una oportunidad indudable para la práctica traductológica, la familiarización con entornos colaborativos de trabajo (que en la actualidad está a la orden del día), e incluso para ir consolidando nuestra reputación como profesionales. Por otro lado, podemos servirnos de ella como base de datos terminológica o glosario; siempre teniendo en cuenta que el contenido es libre y abierto, y por tanto, resulta necesario filtrar y corroborar la información que buscamos y encontramos.
BIBLIOGRAFÍA:
- http://es.wikipedia.org/
- http://www.fundacion.telefonica.com/es/que_hacemos/conocimiento/
- http://ciberprensa.com/cuales-son-tus-redes-sociales-favoritas/
- http://tecnologia21.com/001-wikipedia-convierte-libro-5000-paginas
- http://educacionvisualwanda.blogspot.com/
Estos entornos colaborativos abarcan desde los editores de documentos compartidos como Google Docs, sitios web abiertos y editables como los wikis, foros y blogs como MySpace o Blogger, o incluso las notorias redes sociales como Twitter o Facebook, que incluyen perfiles y herramientas de conexión para aportan un enfoque colaborativo dentro de la comunidad.
Todas estas plataformas virtuales (e inumerables más) se han convertido en herramientas muy potentes dentro de nuestra sociedad; tanto a nivel personal como educativo, profesional, lúdico, publicitario, etc. En lo que a nosotros respecta, las TICs se presentan como un conjunto de soluciones que permiten crear y organizar entornos, fomentando un flujo dinámico de intercambio de información. Como futuros traductores estas herramientas pueden ser de gran utilidad en nuestras prácticas traductológicas; incluso traducir documentos pertenecientes a ese propio entorno puede llegar a ser nuestro objetivo. Por ello en esta entrada profundizaremos en el funcionamiento de Wikipedia, por ser probablemente el entorno colaborativo más notorio y extenso. Además de contener un número ridículo de artículos y trabajar con casi 300 lenguas, posee una red de herramientas "hermanas" dedicadas a variados dominios: un diccionario, una base de datos de citas célebres, un banco de libros de contenido libre, etc.
No hay nada que ilustre con mayor claridad la notoriedad de Wikipedia como el hecho de que resulta innecesrio explicar en qué consiste dicha web. Cualquier persona que esté leyendo este blog habrá utilizado casi de forma diaria dicha plataforma; y un porcentaje representativo habrá incluso participado en el proyecto editando entradas o utilizándolo como referencia. Sin embargo, dicha notoriedad resulta a veces un arma de doble filo: la pluralidad de usuarios y sus objetivos dispares a veces provocan que la información que Wikipedia contiene sea tendenciosa o falsa. Y a menudo -y es ésta la cuestión que más nos interesa-, las traducciones que se han efectuado de una lengua a otra han sido descuidadas y negligentes, lo que acarrea malentendidos y falsos sentidos.
Por ello, si queremos formar parte de este gran proyecto colaborativo, lo primero que debemos hacer es repasar las normas generales y ayudas básicas que esta web proporciona en su "Portal de la comunidad". En primer lugar, para la orientación de nuevos usuarios, Wikipedia cuenta con una serie de ayudas como una introducción general a cuestiones básicas, una zona de pruebas para practicar creando nuevas entradas, e incluso un programa de tutorías en el que un conjunto de usuarios veteranos voluntarios se ofrecen a actuar como tutores.
También cabe resaltar una sección que a mi modo de ver resulta muy certera: una especie de declaración de lo que Wikipedia no es. Creo que este aspecto merece mención pues saca a la luz lo revolucionario de Wikipedia en sí; lo que hizo que desde sus orígenes surgiera como una propuesta innovadora que relegaría al pasado a las ya arcaicas colecciones enciclopédicas.
Dado el amplio abanico de posibilidades de colaboración dentro de este entorno, considero que lo más útil sería recalcar también aquellos sectores en los que la labor de un traductor resulta más conveniente y favorable. En este sentido Wikipedia cuenta con la sección "Cómo puedes colaborar", en la que solicitan individuos bilingües tanto para traducir desde otras wikipedias al español, como para corregir traducciones "dudosas" ya emitidas. Por otro lado, proponen una serie de recomendaciones a la hora de traducir un artículo; así como un taller idiomático en el que ofrecen apoyo en la traducción de pasajes, frases, modismos, argots, etc.
Resumiendo, por un lado, Wikipedia representa para futuros traductores como nosotros una oportunidad indudable para la práctica traductológica, la familiarización con entornos colaborativos de trabajo (que en la actualidad está a la orden del día), e incluso para ir consolidando nuestra reputación como profesionales. Por otro lado, podemos servirnos de ella como base de datos terminológica o glosario; siempre teniendo en cuenta que el contenido es libre y abierto, y por tanto, resulta necesario filtrar y corroborar la información que buscamos y encontramos.
BIBLIOGRAFÍA:
- http://es.wikipedia.org/
- http://www.fundacion.telefonica.com/es/que_hacemos/conocimiento/
- http://ciberprensa.com/cuales-son-tus-redes-sociales-favoritas/
- http://tecnologia21.com/001-wikipedia-convierte-libro-5000-paginas
- http://educacionvisualwanda.blogspot.com/
sábado, 4 de febrero de 2012
La explotación de textos electrónicos
Hoy en día es muy importante para cualquier traductor saber manejar todo tipo de herramientas TAO y sacarles el mayor rendimiento posible. De ese modo nos ahorraremos tiempo de maquetación y corrección del documento, que podremos utilizar para mejorar la propia traducción en sí. A continuación repasaremos algunas cuestiones que nos ayudarán a explotar las propiedades y posibilidades de los textos electrónicos, y que nos serán muy útiles en futuras labores de traducción. También analizaremos algunas funciones avanzadas de MS Word.
Edición de textos.
1. Plantillas de formato. Normalmente los traductores reciben las plantillas directamente del cliente, pues éste busca que la documentación sea constistente y tenga un formato unificado. A continuación explicaremos paso por paso cómo usar, modificar y copiar estilos:
· Menú Inicio > Apartado Estilos
· Selección texto con formato para copiar > Menú Inicio > Apartado Copiar formato > Selección texto con formato para modificar
2. Instalación de fuentes TT. Para evitar no poder visualizar y trabajar con documentos en su formato y tipografía originales, y tener luego que volver a modificarlos para la entrega al cliente, una posible solución es instalar las fuentes True Type
· Logotipo Office > Apartado Opciones de Word > Abrir pestaña Guardar > Activar casilla Incrustar fuentes en el archivo Activar casilla Incrustar sólo los caracteres utilizados en el documento
3. Mantenimiento de índices y tablas de contenido. Para textos extensos que sufren varias manipulaciones, modificaciones, correcciones, revisiones, etc.
· Crear índices tablas de contenidos
Apartado Referencias > Pestaña Tabla de contenido
· Actualizar índices y tablas de contenidos
Apartado Menú contextual > Pestaña Actualizar campos
4. Convertir tablas en texto. Dado que muchas de las BDDT y las MT no pueden ser alimentadas por tablas, resulta conveniente para cualquier traductor saber cómo extraer de ellas el texto contenido.
· Selección de la tabla > Menú Insertar > Apartado Tabla > Casilla Convertir texto en tabla > Seleccionar Tabulación
· Ordenar texto de tablas
Selección de la tabla > Menú Presentación > Apartado Ordenar > Casilla Ordenar por > Seleccionar Utilizando
Correción y revisión de textos.
1. Diccionarios personalizas. A parte de la herramienta tradicional de Word Revisar: Ortografía y Gramática, se puede agregar un diccionario externo a la lista que tenga instalado en su ordenador.
· Menú Revisar > Apartado Ortografía y gramática > Opción Revisión > Casilla Opciones > Seleccionar Diccionarios personalizados
2. Control de cambios y revisiones de un documento. Cualquier encargo de traducción debe pasar por al menos un revisor o corrector que analice el texto desde el punto de vista técnico y lingüístico. Resulta muy útil para el traductor poder visualizar dichos cambios en su documento.
· Corrección & Seguimiento de cambios
Menú Revisar > Apartado Control de cambios > Opción Cambiar opciones de seguimiento
· Revisión de cambios
Menú Revisar > Apartado Cambios > Opción Aceptar o rechazar cambio
· Comentarios de revisión
Menú Revisar > Apartado Control de cambios > Opción Nuevo comentario / Rechazar cambio / Borrar comentario
3. Comparación de dos versiones de un documento.
· Menú Revisar > Apartado Comparar y Combinar documentos
4. Recuento de palabras.
· Selección texto > Menú Revisar > Apartado Revisión > Opción Contar palabras
Funciones avanzadas de MS Word.
Durante la traducción, cometemos a vecs pequeños errores tipográficos; corregirlos de forma manual sería tan laborioso como tedioso. También existen casos en los que cierto formato de expresión en una lengua difiere en otra; por ejemplo, el uso inglés o el español de comas o puntos en cifras númericas, Existe en Word una forma rápida de cambiar todo tipo de pequeños detalles: las opciones Find y Replace. Para obtener todo tipo de ejemplos al respecto, consultar este artículo de T. Környei; a continuación señalaremos sólo algunos de ellos.
1. Eliminar espacios de sobra.
Find what: •{2,}
Replace with: •
2. Cambio de caracter entre cifras.
· Del "1,000,000.32" inglés al "1 000 000,32" español:
Find what: ([0-9]),([0-9])
Replace with: \1^s\2
---
Find what: ([0-9]).([0-9])
Replace with: \1,\2
· Del "1 000 000,32" español al "1,000,000.32" inglés:
Find what: ([0-9]),([0-9])
Replace with: \1.\2
---
Find what: ([0-9])^s([0-9])
Replace with: \1,\2
3. Invertir numeral y sustantivo.
· Del "2. fejezet", "2. fejezetben" or "2. Fejezet" del húngaro al "Capítulo 2" del español.
Find what: ([0-9]{1,}).?([Ff]ejeze[a-z]{1,})
Replace with: Capítulo^s\1
4. Conversión de símbolos de moneda.
· Del "$50,12" al "50,12 dollars"
Find what: $([0-9.,]{1,})
Replace with: \1^s$
---
Find what: $([0-9.,]{1,})
Replace with: \1^sdollar
BIBLIOGRAFÍA:
- http://es.wikipedia.org/
- http://helpdesk.reformjudaism.org.uk/
Edición de textos.
1. Plantillas de formato. Normalmente los traductores reciben las plantillas directamente del cliente, pues éste busca que la documentación sea constistente y tenga un formato unificado. A continuación explicaremos paso por paso cómo usar, modificar y copiar estilos:
· Menú Inicio > Apartado Estilos
· Selección texto con formato para copiar > Menú Inicio > Apartado Copiar formato > Selección texto con formato para modificar
2. Instalación de fuentes TT. Para evitar no poder visualizar y trabajar con documentos en su formato y tipografía originales, y tener luego que volver a modificarlos para la entrega al cliente, una posible solución es instalar las fuentes True Type
· Logotipo Office > Apartado Opciones de Word > Abrir pestaña Guardar > Activar casilla Incrustar fuentes en el archivo Activar casilla Incrustar sólo los caracteres utilizados en el documento
3. Mantenimiento de índices y tablas de contenido. Para textos extensos que sufren varias manipulaciones, modificaciones, correcciones, revisiones, etc.
· Crear índices tablas de contenidos
Apartado Referencias > Pestaña Tabla de contenido
· Actualizar índices y tablas de contenidos
Apartado Menú contextual > Pestaña Actualizar campos
4. Convertir tablas en texto. Dado que muchas de las BDDT y las MT no pueden ser alimentadas por tablas, resulta conveniente para cualquier traductor saber cómo extraer de ellas el texto contenido.
· Selección de la tabla > Menú Insertar > Apartado Tabla > Casilla Convertir texto en tabla > Seleccionar Tabulación
· Ordenar texto de tablas
Selección de la tabla > Menú Presentación > Apartado Ordenar > Casilla Ordenar por > Seleccionar Utilizando
Correción y revisión de textos.
1. Diccionarios personalizas. A parte de la herramienta tradicional de Word Revisar: Ortografía y Gramática, se puede agregar un diccionario externo a la lista que tenga instalado en su ordenador.
· Menú Revisar > Apartado Ortografía y gramática > Opción Revisión > Casilla Opciones > Seleccionar Diccionarios personalizados
2. Control de cambios y revisiones de un documento. Cualquier encargo de traducción debe pasar por al menos un revisor o corrector que analice el texto desde el punto de vista técnico y lingüístico. Resulta muy útil para el traductor poder visualizar dichos cambios en su documento.
· Corrección & Seguimiento de cambios
Menú Revisar > Apartado Control de cambios > Opción Cambiar opciones de seguimiento
· Revisión de cambios
Menú Revisar > Apartado Cambios > Opción Aceptar o rechazar cambio
· Comentarios de revisión
Menú Revisar > Apartado Control de cambios > Opción Nuevo comentario / Rechazar cambio / Borrar comentario
3. Comparación de dos versiones de un documento.
· Menú Revisar > Apartado Comparar y Combinar documentos
4. Recuento de palabras.
· Selección texto > Menú Revisar > Apartado Revisión > Opción Contar palabras
Funciones avanzadas de MS Word.
Durante la traducción, cometemos a vecs pequeños errores tipográficos; corregirlos de forma manual sería tan laborioso como tedioso. También existen casos en los que cierto formato de expresión en una lengua difiere en otra; por ejemplo, el uso inglés o el español de comas o puntos en cifras númericas, Existe en Word una forma rápida de cambiar todo tipo de pequeños detalles: las opciones Find y Replace. Para obtener todo tipo de ejemplos al respecto, consultar este artículo de T. Környei; a continuación señalaremos sólo algunos de ellos.
1. Eliminar espacios de sobra.
Find what: •{2,}
Replace with: •
2. Cambio de caracter entre cifras.
· Del "1,000,000.32" inglés al "1 000 000,32" español:
Find what: ([0-9]),([0-9])
Replace with: \1^s\2
---
Find what: ([0-9]).([0-9])
Replace with: \1,\2
· Del "1 000 000,32" español al "1,000,000.32" inglés:
Find what: ([0-9]),([0-9])
Replace with: \1.\2
---
Find what: ([0-9])^s([0-9])
Replace with: \1,\2
3. Invertir numeral y sustantivo.
· Del "2. fejezet", "2. fejezetben" or "2. Fejezet" del húngaro al "Capítulo 2" del español.
Find what: ([0-9]{1,}).?([Ff]ejeze[a-z]{1,})
Replace with: Capítulo^s\1
4. Conversión de símbolos de moneda.
· Del "$50,12" al "50,12 dollars"
Find what: $([0-9.,]{1,})
Replace with: \1^s$
---
Find what: $([0-9.,]{1,})
Replace with: \1^sdollar
BIBLIOGRAFÍA:
- http://es.wikipedia.org/
- http://helpdesk.reformjudaism.org.uk/
Suscribirse a:
Entradas (Atom)